Building a RAG Pipeline to Reduce LLM Hallucination
Building a RAG Pipeline to Reduce LLM Hallucination
Problem
At PNU x Upstage DOCUMENT AI CHALLENGE, I developed “DocDoc,” an AI service for overseas medical teams. It was a chatbot that finds relevant papers and answers questions from medical professionals.
At first, I just passed questions directly to the LLM. But problems quickly emerged.
Hallucination:
- The LLM would give plausible-sounding answers that were completely wrong
- Sometimes it even cited papers that didn’t exist
- In the medical field, wrong information can be fatal
Solution: RAG (Retrieval-Augmented Generation)
The idea is to search for relevant documents first and feed them as context before the LLM generates a response.
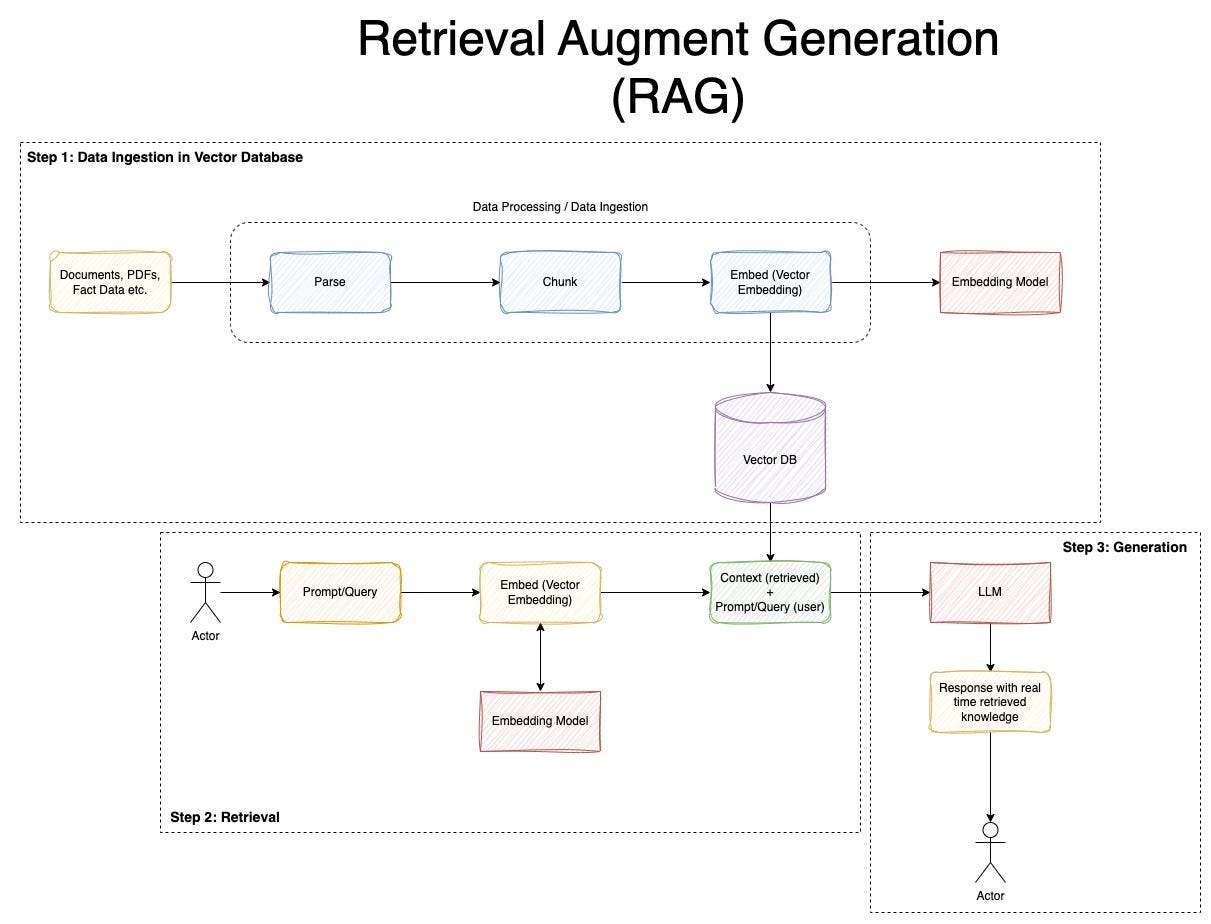
Pipeline:
- Convert the user’s question into an embedding vector
- Search for similar paper chunks in Pinecone (Vector DB)
- Pass the retrieved content as context to the LLM
- LLM generates an answer based on the context
Tech Stack
- Vector DB: Pinecone
- Embedding: Upstage Embeddings
- LLM: Upstage Solar Pro 2
- Framework: LangChain
- Backend: Node.js, Express
UX Improvement: Server-Sent Events
LLM response generation was slow. Users staring at a blank screen might leave.
Solution: EventStream (SSE)
- Stream the answer in real-time as it’s generated
- Characters appear one by one, like ChatGPT
- Users can see that a response is being generated
Lessons Learned
- LLMs aren’t magic. In specialized domains, hallucination is a serious issue.
- With RAG, the LLM answers based on actual documents, improving accuracy.
- Long response times can be mitigated with streaming.
From developing “DocDoc,” which advanced to the finals at PNU x Upstage DOCUMENT AI CHALLENGE 2025.
This post is licensed under CC BY 4.0 by the author.